




1. Quantität als Hindernis bei der sachlichen Erschließung
In "bibliothekarischen Massendaten"2) begegnet uns nichts anderes als die sogenannte Informationsflut. Welcher Bibliothekar wäre nicht schon einmal stolz darauf gewesen, an der großen Aufgabe ihrer Kanalisierung mitzuwirken? Denn nicht darin besteht unsere Leistung, daß wir den Benutzer der Fülle der Information aussetzen, vielmehr ist es Ziel gerade der Sacherschließung, diese Fülle verwertbar zu machen. Nun sind auch konventionelle Dokumente aus dem bibliothekarischen Bereich inhaltlich noch zu wenig erschlossen; zunächst fehlen einfach oft elementare Daten, worauf ja auch das Projekt MILOS auf seine Art zu reagieren sucht. Solche Defizite müssen behoben werden, denn wo keine (oder nur formale) Daten sind, da greift auch kein inhaltliches Retrieval.
Aber breitere und tiefere Erschließung, maschinelle Indexierung in bibliographischen Datenbanken, dazu von Volltexten, die vielleicht nur in Datennetzen existieren, erzeugen auf der anderen Seite, in den Indices "Massendaten", Mengen, die bei Online-Suchen mit gängigen Termini schon in OPACs enorme Trefferzahlen ergeben können.
Schon heute sieht dies bei Schlagwort- und Stichwortsuche etwa so aus:
-------------------------------------------
Trefferzahlen in OPACs und Verbunddatenbanken (Mai 1996): Suche mit Schlagwort
| UB Augsburg | UB Kaisersl. | BVB-KAT (SW-Datei) | SWB WWW-OPAC | |
| USA | 12.857 | 399 | 71.727 | 6.247 |
| Literatur | 15.772 | 64 | 57.672 | 12.541 |
| Recht | 3.858 | 460 | 19.566 | 9.855 |
| Bibliographie | 12.026 | 707 | 56.324 | 10.371 |
| Österreich | 3.283 | 171 | 17.221 | 4.392 |
| Weltkrieg | 1.277 | 12 | 8.731 | 1299 |
| Nietzsche | 374 | 5 | 1.135 | 425 |
| USA Literatur | 1.092 | |||
| USA Recht | 97 |
Es zeigt sich, daß im lokalen OPAC die Suche mit einzelnen gängigen Deskriptoren auf Trefferzahlen im Tausenderbereich stößt und sogar bei UND-Verknüpfung zweier Begriffe bereits mehr als 1000 Treffer erzielt werden können.
Die jährliche Zuwachsrate bei den mit einem bestimmten Suchbegriff bei der Schlagwortsuche im OPAC erzielten Treffern liegt nach einem Test an der UB Augsburg zur Zeit zwischen 4 und 7 Prozent; die Zuwachsrate hat selbst steigende Tendenz. Gleiches gilt für die Suche mit Titelstichwörtern. In Verbunddatenbanken mit konventioneller bibliothekarischer Sacherschließung verhält es sich ähnlich. Die Trefferzahl im BVB-Verbund-OPAC ist beim Schlagwort etwa fünf- bis sechsmal so hoch wie im OPAC einer Universitätsbibliothek und wächst proportional. Diese Zahlen werden in Zukunft weit übertroffen durch die stärkere Berücksichtigung von Nichtbuchmedien, Aufsätzen und Computerdateien, aber auch durch die Indexierung von Volltexten, im Rahmen unserer Kataloge. Trefferzahlen können auch steigen durch retrievalspezifische Techniken der automatischen Expansion von Suchergebnissen im verbalen oder klassifikatorischen Bereich (z. B. beim maschinellen sog. Relevance feedback).
Umso wichtiger wird es, mit diesen Mengen so umzugehen, daß sie für den Endbenutzer verwertbar sind. Diese offenbar trotz vieler Spezialuntersuchungen in der bibliothekarischen Allgemeinheit schwer eingängige Problematik ist aktueller denn je: ein Literaturnachweissystem soll die Mengenprobleme der Information bewältigen helfen; es darf sie weder ignorieren noch gar verschärfen. Leider wird jedoch die momentane Tendenz zu Globalisierung, Simultaneität, Geschwindigkeit und quantitativem Gigantismus im Datenangebot nicht von einem entsprechenden Bewußtsein für die Sicherung der Qualität von Suchergebnissen aus der Sicht des Benutzers begleitet.
Man muß Menge und Vielfalt an Information anbieten, aber zugleich ihre Strukturierung, Reduktion und Konzentration beim Retrieval konsequent unterstützen, weil dies kognitionspsychologisch und arbeitsökonomisch absolut notwendig ist. Schon aus diesen Gründen stellt sich annähernd die Aufgabe, eine Trefferzahl, die zwischen 100 und 1000 oder gar noch höher liegt, auf etwa 10 - 20 % herunterzubringen, wobei dieser Rest möglichst viele hochrelevante Dokumente enthalten sollte.
Wenn wir von Online-Katalogen sprechen, beziehen wir uns auf die bibliothekarische Domäne bibliographischer Datenbanken. Das ist durchaus etwas anderes als Ganz-Dokumente, die mit Volltext-Retrievalsystemen erschlossen werden können. Zwar sollen Volltexte und ihre bibliographische Beschreibung verknüpft werden; der suchende Zugriff auf beide ist aber unterschiedlich: Suche über die Dokumente hinweg und Suche innerhalb eines Dokuments erfordern eigene Strategien.
Online-Kataloge sind in aller Regel multidisziplinäre Datenbanken. Daraus ergeben sich nicht unbedingt größere Treffermengen als in Fachdatenbanken, aber jedenfalls ein umfangreicheres und heterogeneres Vokabular, das sich auf ein weit heterogeneres Dokumentenmaterial bezieht. Die Konsequenz ist leider, verglichen mit fachlich begrenzten Informationssystemen, ein Mangel an Voraussehbarkeit und Übersichtlichkeit bei der Darstellung von Suchergebnissen, dem man durch ein eigenes Design des Erschließungsverfahrens und des Suchablaufs begegnen muß.
Ich möchte den Begriff des Indexats benutzen und meine damit alle zum Zweck inhaltlicher Erschließung erstellten und zur Wiedergabe von Dokumentinhalten bereitgestellten Daten. Dies können sowohl Schlagwortketten als auch einzelne oder gereihte Deskriptoren sein. Sie haben jedoch zwei wesentliche Funktionen:
2. Der Suchprozeß
Ich beziehe die informationstheoretischen Grundlagen der Thematik auf die Ebene heutiger bibliothekarischer Online-Kataloge mit RSWK-Schlagwortdaten, glaube aber doch, damit dem Stand der allgemeinen Erkenntnisse zur Informationsgewinnung gerecht zu werden, auf dessen Basis die nächste OPAC-Generation in einer Welt der Netze gestaltet werden muß, ob nun RSWK-Daten angeboten werden oder nicht.
2.1. Suchstrategien
Man unterscheidet bei der sachlichen Suche zwei grundlegende Strategien:
Die analytische Suche fordert eine genaue Definition der Fragestellung, Zielplanung und Festlegung der Suchbegriffe, am Ende eine gründliche Analyse der Ergebnisse. Sie basiert auf Booleschen Operatoren, ist formal, kognitiv anspruchsvoll, kann aber auch auf Vermittler übertragen werden. Suchanfrage und Ergebnisanalyse sind zwei getrennte Schritte. Der dazwischenliegende maschinelle Suchvorgang läuft sehr schnell ab. So verfährt die klassische Recherche in kostenpflichtigen Fachdatenbanken.
Dagegen verläuft die Browsing-Suche heuristisch, erfordert weniger Vorarbeit, aber mehr Aufmerksamkeit und Aktivität im Suchprozeß. Weil sie weniger planbar ist und mehr vom Datenangebot des Systems angeregt wird (man könnte sagen, der Benutzer informiert sich weniger, er läßt sich informieren), ist sie nicht logische Folge einer (vielleicht defizitären) Suchformulierung, sondern lebt vom okkasionellen Erkennen relevanter Informationen, die auch überraschend auftauchen können. Suchanfrage und Ergebnisauswertung wechseln ständig oder gehen ineinander über. Browsing ist ein nichtlineares, aktives und potentiell interaktives Lesen, das dem Endbenutzer kein Vermittler abnehmen kann. Die wichtigsten Aktivitäten sind Blättern, Navigieren, Überwachen von Kontext und Umfeld, Auswahl durch Markieren aus Menüs und Listen. Damit verbinden sich Relevanzeinschätzung, Identifikation und Vergleich. All dies kann Zeit kosten, aber ungeahnte Erfolge bringen. Es gibt Erfahrungen, wonach eine Brainstorming-Phase durch Browsing-Aktivitäten am fruchtbarsten genutzt werden kann.
Nun liegt diese Methode in der Natur des Menschen, sie entspricht der Art und Weise, wie wir ein simultanes Angebot in Warenhäusern, die Vielfalt der Medienprogramme oder auch die Präsentation von Exponaten in Museen und von Büchern in Freihandbibliotheken wahrnehmen und nutzen. Dieses Informationsverhalten läßt sich bei einer Online-Suche auf keinen Fall verhindern - im Gegenteil: es muß genauso wie die analytische Suchstrategie unterstützt werden3), weil es gerade der elektronischen Umgebung höchst adäquat ist, wie ja auch das Bewegen im Hypertext und das Surfen im Internet typische Browsing-Aktivitäten sind.
Zielloses Herumschweifen in großen Datenmengen ist nun aber nicht effektiv, deshalb sollte das Browsen bei sachlicher Suche wenigstens teilweise zielorientiert in vorausgewählten Daten stattfinden. Sinnvollerweise bildet also eine analytische Suche den Einstieg.
Leider sind heute die meisten OPAC-Oberflächen zu stark auf die Analyse einer Suchformulierung fixiert und vernachlässigen das informelle Browsing, Problemfeedback und -bewertung sowie die selektive Gewinnung relevanter Information. Zu oft hat man den Eindruck, ein OPAC-System lauere nur darauf, dem Benutzer einen ungeordneten Haufen Treffer hinzuwerfen, um ihn für eine Sucheingabe zu bestrafen. Im schlimmsten Fall endet die Suche wie eine Einbahnstraße, die zugleich eine Sackgasse bildet. Eine Erklärung dieses verbreiteten Mißstandes könnte sein, daß Probleme der Wahrnehmung gegenüber rein kognitiven und formal-logischen Aspekten unterbewertet werden4). Es ist aber unwahrscheinlich, daß irgendein Informationssystem als ausgereift gelten kann, ohne sowohl analytische als auch Browsing-Suchstrategien zu unterstützen5).
2.2. Mensch-Maschine-Kommunikation
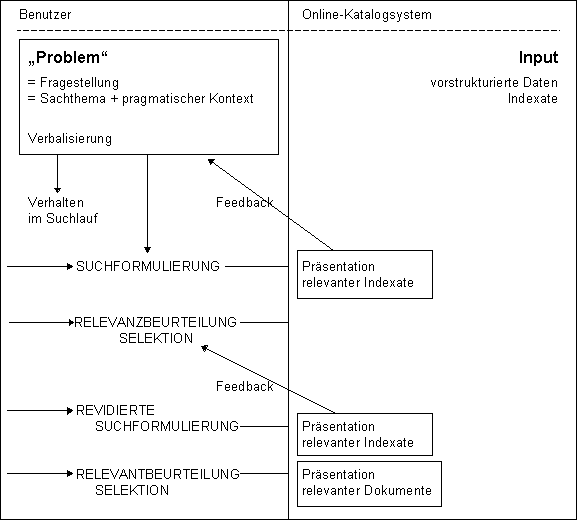
Die thematische Suche beginnt nicht mit dem ersten Tastendruck und endet selten mit der Anzeige der erstbesten Trefferliste
(vgl. Abb.).
So wie die Indexate Surrogate des Dokumentinhalts sind, so ist die Suchformulierung immer nur ein Surrogat der eigentlichen Fragestellung, also des Informationsbedürfnisses, der Wissenslücke, des Problems, das zahlreiche mentale Vorstellungen oder Erinnerungen in Gang setzen kann, aus denen sich Begriffe ergeben. Diese Begriffe werden am Ende möglicherweise verbalisiert zu einer Suchformulierung. Jedoch nicht nur in dieser manifestiert (besser: spiegelt) sich die Fragestellung des Benutzers, sondern auch in seinem gesamten Verhalten während des Dialogs mit dem System, z. B. in seiner Reaktion auf Ergebnisanzeigen und im Wechsel der Suchstrategie bzw. -taktik. Ein Suchprozeß wird teilweise von der Fragestellung, teilweise von den angezeigten Daten beeinflußt und gelenkt.
Es ist zu bedenken, daß die meisten Benutzer Dokumente suchen müssen, um daraus informative "essentials" zu gewinnen, die ihrem "Problem" entsprechen, seien es Fakten oder Interpretationen, während das System nur die Dokumente selbst mit spärlichen inhaltsbezogenen und formalisierten Daten nachweist. Demgegenüber ist es die große Ausnahme, daß jemand die gesamte Literatur zu einem Themenbereich verwerten will, der sich exakt beschreiben läßt.
Wir sollten auch bedenken, daß zum "Problem" vieles gehört, das sich nicht verbalisieren läßt, z. B. wenn jemand nur aktuelle Aspekte einer Sache sucht, keinesfalls die historischen, oder lediglich kurze und leicht verständliche Texte auf deutsch zu lesen bereit ist oder mit anderen Medienformen als Gedrucktem nichts anfangen kann. Eine große Rolle spielen auch zeitliche, räumliche, technische und kostenmäßige Voraussetzungen und Erwartungen. Die Relevanz von Suchergebnissen hängt auch stark von solchen pragmatischen Faktoren der Anfragesituation ab. Jedenfalls ist also die implizite Frage (das Problem) von der expliziten (der Sucheingabe) klar zu unterscheiden. Der wirkliche Sucherfolg ist am impliziten Informationsbedürfnis zu messen.
2.3. Iterative Suche
Die dem Problem nicht entsprechenden Teile einer Treffermenge, also den Ballast, auszublenden, ist eine essentielle Aufgabe, bei der das System Unterstützung bieten muß, sonst ist es bei thematischer Suche kaum noch möglich, effektiv zu brauchbaren Ergebnissen zu kommen.
Ein Erschließungssystem muß den Benutzer z. B. durch Hinweise am Bildschirm darauf vorbereiten, daß eine Filterung der erzielten Treffer notwendig werden kann, und ihm interaktiv dabei helfen. Ihn lediglich zur Eingrenzung durch die Eingabe zusätzlicher Suchwörter aufzufordern, unterstellt, daß die Sucheingabe - gemessen an der eigentlichen Fragestellung - zu vage war. Häufig impliziert aber das Ausgangsproblem keine weitere Spezifizierung. Bricht der OPAC also die Suche ab, ohne zu zeigen, in welche Richtung sie weitergehen kann, so muß der Benutzer oft einen dem Problem adäquaten Sucheinstieg ohne innere Konsequenz abändern. Damit wird ein iteratives, d. h. aufbauendes und fortschreitendes Browsing verhindert und eine in dieser Situation meistens nicht effektive, weil unter Zeitdruck kaum reflektierbare neue Eingabe erzwungen.
Das Prinzip einer Selektion aus inhaltsbeschreibenden Daten muß sein, auf eine überschaubare Zahl relevanter Dokumente zu kommen, ohne die primäre Suchformulierung explizit zu revidieren. Vielfach wird sich die Suche angesichts der gezeigten Indexate präzisieren lassen, oder auch weiter entfalten und verzweigen. Es gibt dann keinen Abbruch, kein ratloses Zurück, sondern einen Fortschritt. Das System gibt dem Benutzer Rat auf der sachlichen Ebene mit sachlichen Daten; es fördert leichte Modifikationen und kleine Schritte zum Sucherfolg, anstatt nur Mißerfolge zu bescheinigen. Gleich wie hoch die Trefferzahl zunächst war, ist das zu erreichen, indem das Suchergebnis in sachlich rasch beurteilbarer und direkt verwertbarer Form übermittelt wird.
2.4. Präkoordination
Wenn ein Benutzer analytisch, postkoordinierend sucht, geht er wohl von syntagmatischen Beziehungen zwischen Begriffen aus, d. h. einer (auf die gespeicherten Deskriptoren bezogen) postkoordinierenden Suche im OPAC geht eine (auf die Fragestellung bezogen) präkoordinierende Verbalisierung voraus. Daneben kommen auch Präkombinationen, z. B. Komposita, sowohl in der Suchformulierung als auch in den Indexaten vor. Diese Annahme spricht dafür, bis zu präkoordinierten Verknüpfungen von Deskriptoren verdichtete Texte, die ihrerseits auch komplexere Termini enthalten, als Inhaltsbeschreibungen einzusetzen.
3. Verwertung von Indexaten als Zwischenergebnis
Indexate leisten als angezeigte Daten folgendes: Sie sind gegenstandsbezogen und können direkt und präzise zu vorhandenen Dokumenten hinführen; sie bieten dem Benutzer außerdem Vokabular als Verbalisierungshilfe für weitere Aspekte seines Problems, ohne daß er hierzu eigener formulierender Suchschritte bedarf. Zeitaufwendige Rückgriffe auf Deskriptorenlisten und Normdateien sind somit oft vermeidbar. Indexate sind kompakter darstellbar als Katalogisate; bei der Zwischenanzeige ergeben sich außerdem geringere Treffermengen als bei den entsprechenden Titeln. Substantielle und gut präsentierte, z. B. auch geordnete Trefferinformationen können daher auch für den Suchenden zur Durchsicht attraktiv sein.
3.1. Vorstrukturierung Input und Output
Mit zunehmendem Umfang der Treffersets wird es immer wichtiger, ob und wie sie organisiert und geordnet sind. Effektives Browsing setzt eine hochgradige Vorstrukturierung voraus. Bei sachlichem Browsing am Regal in Freihandbibliotheken ist dies die systematische Aufstellung, im Katalog die Organisation der Daten nach inhaltlichen Kriterien. Hierzu gehört die erwähnte Präkoordination von Deskriptoren nach dem Muster der sprachlichen Struktur der Begriffe im Kopf des Suchenden.
3.2. Deskriptiver Wert der Indexate
Die deskriptive und gliedernde Qualität von Indexaten beruht auf dem Grundsatz der Spezifität, d. h. das Indexat will begrifflich einem im Dokument behandelten Gegenstand entsprechen. Das bedeutet, daß allgemeine und spezifische Thematiken unterschieden werden, auch wenn für alle der gleiche Deskriptor benutzt wurde.
Da Browsing nichtlineares Lesen ist, muß es von Indexaten ausgehen und zwischen ihnen springen können. Das Systemdesign ist gefordert, diese Zugriffe so komfortabel wie möglich zu präsentieren durch eine voraussehbare und konsistente Darstellung, d. h. Plazierung der entscheidenden Daten wie Schlagwörter, Menüpunkte, Icons usw., um die rasche Koordination von Augen-und Handbewegungen, auf die es beim Browsen in Online-Systemen entscheidend ankommt, zu erleichtern6).
Das Indexat transportiert eine grobe, aber besonders im fachübergreifenden Umfeld notwendige semantische Differenzierung, z. B. die Trennung von Homonymen. Aus der heute üblichen und im allgemeinen auch sinnvollen Verstichwortung der Indexate für die Suche resultiert, daß im Einzelfall nicht relevante Begriffe und Bedeutungsvarianten auszuklammern sind.
------------------------------------------------------------------------------------------
Ihre Suche: Schlagwort | | FRAU KIRCHE | |Trefferzahl: 61------------------------------------------------------------------------------------------Bitte kreuzen Sie an, was Sie interessiert, und drücken Sie dann F 5 !
| Frau / Kirche | 3 Titel |
| Frau / Priesterweihe / Orthodoxe Kirche | 1 Titel |
| Evangelische Kirche / Frau / Erlebnisbericht | 1 Titel |
| Evangelische Kirche in Berlin-Brandenburg / Frau / Kirchenkampf <1933-1945> | 1 Titel |
| Priester / Katholische Kirche / Frau / Interview | 1 Titel |
| Anglikanische Kirche / Frau / Geschichte 1980-1990 | 1 Titel |
| Entwicklungsländer / Frau / Kirche | 1 Titel |
| Lutherische Kirche / Frau / Ordination | 2 Titel |
| USA / Südstaaten / Frau / Evangelische Kirche / Geschichte 1830-1900 | 1 Titel |
| Kirche / Frau / Geschichte 1130-1215 | 1 Titel |
| Evangelisch-Lutherische Kirche in Bayern / Frau / Kongreß / Tutzing <1987> | 1 Titel |
| Deutschland / Evangelische Kirche / Frau / Geschichte 1899-1947 | 1 Titel |
| Kirche / Frau / Liturgie | 1 Titel |
| Katholische Kirche / Frau | 5 Titel |
| Ordination / Frau / Katholische Kirche | 1 Titel |
| Frau / Kirche / Bibliographie | 1 Titel |
| Orthodoxe Kirche / Frau | 1 Titel |
| Gemeindearbeit / Frau / Evangelische Kirche / Erlebnisbericht | 1 Titel |
| Anglikanische Kirche / Frau / Kirchliches Amt / Geschichte | 1 Titel |
| Johannes <Chrysostomus> / Frau / Kirche | 1 Titel |
| Mariologie / Frau / Katholische Kirche | 1 Titel |
------------------------------------------------------------------------------------------
3.3. Präsentation von Informationen mit Selektionsmöglichkeit
Am Grundprinzip der sequentiellen Informationsdarbietung und -verarbeitung ändert sich auch in Online-Systemen nicht viel. Listen von Indexaten können - auch als Element nichtlinearen Browsings - linear oder selektiv rezipiert werden, in jedem Fall müssen sie klar und konzis sein. Was innerhalb eines Dokuments als extensives oder kursorisches Lesen bezeichnet wird, ist hier die Aufnahme von Inhaltsinformationen über viele Dokumente nacheinander auf engem Raum.
Während die Maßgaben der RSWK zum Auffinden von Eintragungen im Alphabet (etwa die Permutationsregeln) im OPAC an Bedeutung verlieren, bleibt die deskriptive Struktur der Schlagwortketten unverändert wichtig. Diese haben dort ihren Platz als eigenständiger Bereich des Output, wo eine inhaltsbezogene Auswahl aus größeren Datenmengen erforderlich ist. Ihre besondere Qualität liegt in ihrem Textcharakter; sie sind strukturierbar, darstellbar und lesbar.
Daher sind das Erstellen von Abstracts und die intellektuelle Schlagwortvergabe durchaus vergleichbar: sie ermöglichen das Herausfiltern von Information über die Relevanz einzelner Dokumente. Beide sind sowohl als Texte verstehbar und mit Markierfunktionen zu bearbeiten als auch einer Indizierung und maschinellen Auswertung zugänglich. Im Unterschied zu Abstracts sind Schlagwort-Indexate aber durch ihre knappe und gegliederte Form zugleich zur OPAC-gerechten Präsentation in übersichtlichen Listen geeignet.
Ein noch so knapper Text, auch eine kurze Folge von Deskriptoren, liefert nun immer auch Kontext, also zum bekannten Terminus weitere, auf denen ein Browsing aufsetzen kann. Zur effektiven Informationsverwertung wird gerade auch Kontext benötigt, weil hierzu auch begriffliche Orientierung, Differenzierung, Anregung des Weiterdenkens und Extraktion von Kerninformationen gehören.
Die Anzeige und Verwertung der Indexate als Text und Kontext, auch wenn sie redundant sind, hat z. B. gegenüber dem Wechsel in einen Thesaurus oder einer klassifikatorischen Ergänzungs- oder Anschlußsuche den Vorteil, sowohl kognitiv als auch physisch eine homogenere Aktivität zu sein.
In allen Endnutzeroberflächen wächst mit zunehmenden Datenmengen die Bedeutung der Selektion, wozu eine menüartige Präsentation mit komfortablen Markiermöglichkeiten erforderlich ist. Das Prinzip muß sein: so wenig wie möglich verbale Eingabe zu erzwingen, soviel wie möglich durch Markieren auswählen zu lassen. Das gilt auch dann, wenn zur Eingrenzung einer Suche zusätzlich eine Klassifikation zur Verfügung steht. Die Verbalisierungshürde ist sehr hoch.
Zwischen allgemeiner und spezieller Thematik beim Retrieval mit dem gleichen Suchbegriff unterscheiden zu können, ist ein zentrales Problem des Information retrieval, das durch Schlagwortketten als präkoordinierender Kontext, gut lösbar ist. Wir erbringen hier eine intellektuelle, durch maschinelle Verfahren kaum ersetzbare, aber für die künftige Sacherschließung immer wichtigere Leistung. Gibt es denn ein prinzipiell anderes Verfahren, um allgemeine Darstellungen aus der Menge der speziellen Darstellungen herauszufiltern? Jedenfalls muß ein solches Instrument dem Endnutzer in jedem OPAC zur Verfügung stehen.
3.4. Transparentes Feedback und interaktiver Suchablauf
Mißerfolge bei der sachlichen Suche bemessen sich primär quantitativ (keine Treffer, zu viele Treffer, fehlende Information über die Relevanz von Treffern). Zur Qualität des Systems gehört es, solche Mißerfolge zu vermeiden oder zu überwinden. Automatische Abläufe sind also nur soweit benutzerfreundlich, als eine Visualisierung zum interaktiven Eingreifen ins Relevanz-Feedback dort geboten wird, wo inhaltsbeschreibende Daten bei der Modifizierung der Suche und der Trefferselektion helfen können. Eine Liste fragmentarischer Kurztitel erfüllt diese Anforderung nicht.
Es ist nicht damit getan, daß das System auf eine einmalige, explizite Sucheingabe eine Liste formaler Dokumentinformationen ausgibt, vielmehr muß, wenn die Dokumente mit Schlagwörtern indexiert wurden, ein relevanzbezogenes Feedback ("Problemfeedback") auch implizite oder nicht verbalisierte Aspekte der Fragestellung ansprechen; ggf. muß der Benutzer die Unangemessenheit einer Eingabe möglichst frühzeitig und sachlich nachvollziehbar erkennen.
Zum Feedback gehören auch so primitive Dinge wie eine Anzeige der Suchbegriffe während des gesamten Suchvorgangs und eine jederzeit verfügbare Search history. Denn der Output des Systems umfaßt nicht nur Daten, sondern auch den Prozeß, also die gesamte Reaktionsweise des Systems, woraus der Benutzer Schlüsse über dessen Effektivität und die seiner Sucheingabe ziehen kann.
Durch ein Browsing im Anschluß an eine Einstiegs-Suchanfrage kann der Benutzer ihm zunächst nicht präsente Fachterminologie ermitteln und zur weiteren Suche benutzen. In neuen WWW-OPACs ist dies z. T. mit Hyperlinks von der Vollanzeige der einzelnen Titelaufnahme ansatzweise realisiert. Leider wird dort die vorherige Selektion aus Indexaten (noch) nicht angeboten, die ungleich wichtiger ist. Außerdem erlaubt das Hyperlinking bisher nur das Weiterverfolgen eines einzigen Begriffs, keine Booleschen Verknüpfungen7), und birgt die Gefahr der Ablenkung und der erneut zu großen Treffermenge. Man kann solche Links daher nur bedingt als Feedback-Elemente bezeichnen. Nein, es ist falsch, das sachliche Browsing erst auf der Ebene der einzelnen, schon gefundenen Dokumente aufsetzen zu lassen - bereits im Menü der Indexate muß die direkte Manipulation der Informationen durch den Benutzer unterstützt werden.
Transparente Sacherschließung im OPAC soll beim Benutzer nicht Regelkenntnisse voraussetzen, vermittelt aber mit der Anzeige der Indexate zugleich Einsicht in ihre Regelhaftigkeit, eine Art Metainformation, ohne dem Benutzer abstraktes Regelwissen aufzudrängen.
Nun haben wir in deutschen Verbunddatenbanken und OPACs mit den Schlagwortketten Daten, die genau diesen Anforderungen entsprechen. Auch wenn das Vokabular Probleme bereitet und nicht alle Sucheinstiege direkt abgedeckt werden können, ist allein schon durch die Existenz solcher deskriptiver Kurztexte eine Basis für qualitative Suchmöglichkeiten im OPAC gegeben.
Es wird aber auch klar: Sind Erschließung und Retrieval inhaltsbezogen und will man sich nicht mit minimalen Suchergebnissen begnügen, so muß an beiden Stellen ein gewisser intellektueller Aufwand betrieben werden.
4. Relevanz
4.1. Ermittlung von Relevanz
Als relevant betrachtet der Benutzer bei der Ergebnisauswertung diejenigen Treffer, die seinem Erkenntnisinteresse (Problem) unter den Bedingungen der Anfragesituation zu entsprechen scheinen. Größen wie Recall und Precision als linear-eindimensional an einer a priori als relevant definierten Menge von Dokumenten zu messen, wird der Tatsache nicht gerecht, daß die Kriterien für Relevanz durchaus nicht nur aus der expliziten Sucheingabe ableitbar sind.
Wird dennoch versucht, die Relevanz von Dokumenten bei einer analytischen Suche zu ermitteln, so kann sie in Bibliothekskatalogen nicht nur aus dem Vorkommen eines Terminus im Sachtitel hergeleitet werden, da die Übereinstimmung von Titelwörtern mit den wirklichen Themen des Dokuments zu unsicher ist - von der multilingualen Dokumentsprache einmal abgesehen. Intellektuell zum Zweck der Indexierung erstellte Texte, nämlich Abstracts oder Indexate, sind für eine Analyse weit besser geeignet.
Es macht auch wenig Sinn, Gewichtungsalgorithmen auf konventionelle bibliographische Daten anzuwenden, denn nur bei einer Analyse umfangreicher, deskribierender Texte könnte z. B. die Häufigkeit bestimmter Wörter im Text für eine statistische Gewichtung der Treffer herangezogen werden. Nur ein qualitativ orientiertes Verfahren (etwa: Schlagwort vor Stichwort) taugte zur groben Gewichtung bibliographischer Daten, dies setzt jedoch intellektuellen Input voraus.
Die statistische Relevanzermittlung wäre bei einer Suche über viele Dokumente hinweg wenig wirkungsvoll, wenn sie der expliziten Sucheingabe einen internen Suchablauf aufpfropft, in den der Benutzer nicht mehr korrigierend eingreifen kann.
Relevanz ist eine komplexe und sehr wandelbare Größe; daher liegt es nahe, dem Benutzer im Rahmen seiner perzeptiven Belastbarkeit Relevanzmarkierungen anzubieten und ihn auf deren Beurteilung hinzuführen. Relevanzbeurteilung und Selektion sollte eine qualitätsverbessernde Aktivität während des Suchprozesses sein. Auch wenn beim Retrieval statistisch-quantitative Algorithmen eingesetzt werden können, muß im Input die Basis für eine entsprechende Aktivität des Benutzers gelegt und mit einer effektiven Präsentation verbunden werden.
4.2. Relevanzbezogene Selektionshilfen
4.2.1. Kennzeichnung und Gewichtung in der Erschließung
In der verbalen Sacherschließung ist primär die inhaltliche Spezifizierung und Differenzierung, die einer Selektion nach dem Thema dient. Sekundär wäre eine Kennzeichnung der Dokumentform oder des Niveaus der Darstellung, also pragmatischer Elemente, wie sie in den RSWK-Formschlagwörtern existiert.
Unter den nach RSWK vorgesehenen Schlagwortelementen sind zur weiteren Selektion besonders brauchbar die Aspekte Ort, Zeit und Form, da diese Bezüge bei der primären Suche nach Sachthemen oft vom Benutzer nicht berücksichtigt werden, dann aber bei der Selektion stark ins Gewicht fallen können. Es erleichtert die Suche, wenn Inhaltsbeschreibung und zusätzliche Kennzeichnungen wie Darstellungsform oder physische Dokumentform im Indexat kombiniert vorliegen. Als weitere wichtige Kriterien, die aus den Daten der Formalerschließung extrahiert werden müssen, wären das Erscheinungsjahr und die Sprache des Dokuments zu nennen. Hinzu kommt der Einsatz klassifikatorischer Werte. Daß all diese Elemente, auch wenn sie z. T. in codierter Form erfaßt sind, komfortabel retrievalfähig sind und an der richtigen Stelle angezeigt werden, bleiben Desiderate aus der Sicht der verbalen Sacherschließung.
Gerade die zeitliche Zuordnung ist ein Element intellektuellen Inputs, das eine Inhaltsanalyse erfordert. Der Zeitaspekt ist maschinell nicht konsistent extrahierbar.
Es stellt sich die Frage, ob auch der methodische Ansatz der Darstellung als ein Abbild des wissenschaftlichen Diskurses8) stärker in den Indexaten berücksichtigt werden soll, oder etwa gar Anmerkungen empfehlenden Charakters, z. B. für den Bereich der öffentlichen Bibliotheken.
Vieles spricht aber dafür, weitere der Relevanzbeurteilung dienende Elemente nicht in die Indexate zu stopfen, sondern in Form eingescannter Paratexte (Klappentexte, Inhaltsverzeichnisse), Hyperlinks und anderer Hinweise auf verwandte Dokumente zu speichern. Besondere Bedeutung kommt vielleicht künftig den Special-interest-Kennzeichnungen auch lokaler Art zu, die durch den Endbenutzer selbst gestaltet und ergänzt werden können.
4.2.2. Gewichtung durch Nicht-Erschließung
Man fragt sich gelegentlich auch, ob ein selektiver Verzicht auf Sacherschließung (im Sinn von Input) der Qualität im Sinn verwertbarer Retrievalergebnisse dienen kann. Niemand wird bezweifeln, daß der Ausschluß älterer wissenschaftlicher Literatur von der qualitativen intellektuellen Sacherschließung dann sinnvoll ist, wenn das sachliche Informationsbedürfnis durch neuere Dokumente zureichend abgedeckt wird.
Vielleicht kann darüber hinaus beim Input stärker gewichtet werden, um durch bewußte Auswahl und Beschränkung den bei einer durchschnittlichen Suche zu erwartenden Ballast zu vermindern - vielleicht mit dem Hintergedanken, die als minder wichtig eingestuften Dokumente könnten notfalls zum Teil durch eine Freitextsuche im Basis-Index auch ermittelt werden? Dennoch spricht vieles dafür, daß die Relevanzbeurteilung trotz der großen zunächst anfallenden Mengen im Suchprozeß selbst, unter Mitwirkung des Benutzers im Sinn seiner Fragestellung, stattfindet.
5. Integration verschiedener Erschließungsstrategien und Datenschichten
Ebensowenig wie verbale Indexierung dasselbe leisten kann wie eine Klassifikation, können sich intellektuelle Sacherschließung und Volltextretrieval im Online-Katalog gegenseitig ersetzen. Die Schwächen der Volltextinvertierung werden unübersehbar bei wachsendem Dokumentenbestand, wenn die Benutzer erheblichen Aufwand für die Nachselektion in Kauf nehmen müssen.
Große Treffermengen lassen sich jedenfalls mit Gewinn an Präzision mit den Erschließungsverfahren des Internet nicht reduzieren. Solche Verfahren sind geeignet für Suchbegriffe mit geringerer Treffererwartung. Freitextsuche und Suche über Indexate sind einander ergänzende Optionen.
Der Begriff des "Zoomens" (zur Relevanzerkennung zwischen verschiedenen Niveaus der Anzeige wechseln) läßt sich gut auf ein System anwenden, in dem sowohl Volltextdokumente und Paratext als auch bibliographische Surrogate, Indexate, Notationen und Normdaten unter einer flexiblen Suchoberfläche integriert sein werden. Leicht finden die RSWK-Schlagwörter hier neben einem eigengesetzlichen Volltextretrieval ihren Platz als unentbehrliches qualitatives Instrument zur Bewegung und Orientierung in den sonst unüberschaubaren Informationsmengen. Je nach Feedback, je nach Treffermenge und -präzision wird sich dann im Lauf mancher Suche ein Wechsel zwischen verschiedenen Aspekten in der Datenbank anbieten. Die künftige verbale Sacherschließung muß verschiedene Datenschichten integrieren.
Den Stellenwert der intellektuellen Sacherschließung in der gesamten verbalen Erschließung könnte man so veranschaulichen: Innerhalb der gesamten Treffer mit unterschiedlichem Relevanzgrad befindet sich die qualitativ erschlossene und entsprechend darstellbare Datenschicht immer im höherrelevanten Bereich und in dem zuerst angezeigten Abschnitt der Treffermenge. Auch wenn nur dem geringeren Teil der Dokumente solche Daten zugeordnet sind, muß es das Ziel sein, daß in diesem Sektor möglichst viele hochrelevante und rasch verfügbare Informationen enthalten sind, die diesseits der individuellen Grenze der Relevanzeinschätzung des Benutzers und diesseits der Grenze seiner Aufnahmebereitschaft liegen.
Ohne in falsche Konkurrenz zur Freitextsuche zu treten, beweisen RSWK und SWD durch die Ausrichtung an den Funktionen von Indexaten ihre Eignung für diesen quantitativ begrenzten, aber qualitativ hochwertigen Kernbereich; es ist nicht zu bestreiten, daß Schlagwortketten zur effektiven sachlichen Suche in Online-Systemen ganz wesentlich beitragen können.
6. Kosten-Nutzen-Überlegungen
Kosten sind nicht nur die Aufwendungen für den Input, also die Arbeit der Indexierer, und den Betrieb des Systems, vielmehr entscheidet über die kostenmäßige Effektivität des Ganzen hauptsächlich der dem Endbenutzer zugemutete Aufwand, die Inanspruchnahme von Zeit, kognitiven und emotionalen Ressourcen, die gerade im Wissenschaftsbereich ganz erheblich finanziell zu Buche schlagen. Ein Abbau des Inputs und des bereitgehaltenen Outputs aus Kostengründen oder aus falscher Furcht vor Komplexität geht an der Tatsache vorbei, daß Qualität sich auf der Benutzerseite als Nutzen auszahlen muß, und daß zur Erreichung qualitativer Ergebnisse der Benutzer vom Datenangebot und vom System bestmöglich unterstützt werden muß. Vereinfachungen beim Output sollen je nach Problem durch den Benutzer wählbar sein.
Es kommt aber insgesamt teuer zu stehen, wenn man in WWW-OPACs, die ja durchaus zur sachlichen Literatursuche genutzt werden wollen, eine in Bibliotheksverbünden großenteils vorhandene reiche verbale Sacherschließung nach RSWK sowie die elementare Benutzerführung bei inhaltlicher Suche einfach über Bord wirft, wie dies neuerdings hinter der Fassade einer attraktiven graphischen Oberfläche Mode zu werden scheint. Verführerische Hyperlinks können die notwendige Spezifität und Präzision der Erschließung nicht ersetzen. Man kann nur dringend raten, die Informationsgewinnung bei sachlicher Suche baldmöglichst auch im Design weltweit vernetzter OPACs als komplexe, aber notwendige Aufgabe ernst zu nehmen!
7. Was kann künftig "bibliothekarische" Sacherschließung sein?
Als "bibliothekarisch" dürfen wir nicht länger eine Abgrenzung zu "dokumentarisch" ansehen in dem Sinn, daß Aufsätze von der Sacherschließung in Online-Katalogen ausgeschlossen werden. Gerade bei der Erschließung unselbständiger Dokumente ist es sehr wünschenswert, gleiche Verfahren, d. h. mit den gleichen Selektionsmöglichkeiten, anzuwenden, auch wenn das im allgemeinen voll intellektuell nicht zu leisten ist. Dasselbe gilt für elektronische Dokumente.
Als Kriterium einer "bibliothekarischen" verbalen Sacherschließung könnte man heute u. a. sehen, daß nicht nur die Informationsmengen additiv vermehrt, sondern bewußt und gezielt kanalisiert und der menschlichen Aufnahme- und Verarbeitungsfähigkeit adäquat strukturiert werden. Im bibliothekarischen Bereich sollte ein besonderes Bewußtsein für Präzision bei der Suche als Qualitätsmerkmal der Erschließung herrschen und unter Ausnutzung aller Rationalisierungsmöglichkeiten angestrebt werden. Selbstverständlich müssen die vielfältigen Möglichkeiten elektronischer Erschließungstechniken, die dem gleichen Ziel dienen, zum Kerngebiet bibliothekarischer Aufgaben werden. Die Integration intellektueller und maschineller Indexate bildet eine der größten Herausforderungen; es wäre ein Gewinn, auch dort, wo keine intellektuelle Erschließung, sondern nur maschinell-extrahierende Auswertung möglich ist, dennoch lesbare Indexate zu erzeugen.
"Bibliothekarische" Sacherschließung, der lokale oder Verbund-OPAC als kostengünstige Informationsquelle in Allgemeinbibliotheken, ist außerdem für die Disziplinen, die sich großer Fachdatenbanken bedienen können, vielleicht auch generell, in einem Vorfeld angesiedelt, wo bewußt interdisziplinäre Fragestellungen, nichtspezialisierte Benutzer und breite Publikumsschichten mit populärwissenschaftlichem oder im weitesten Sinn literarischem Interesse einbezogen sind. Dem entspricht, daß hier nur eine sachliche Suche mit deutschsprachigen Suchtermini erwartet werden kann - ein Grundsatz, der nicht zur Disposition stehen darf.
Scheint derzeit das Konzept von Bibliothekskatalogen auf dem Weg zu sein, bis zur Unkenntlichkeit mit dem Universum weltweiter Informationsnetze und Fachdatenbanken zu verschmelzen, so ist zu fragen, ob nicht angesichts immer bequemeren Zugriffs auf das Ferne und Spezielle die Besinnung auf Qualitäten dieses "Vorfelds" nottut. Oder sind sachliche Suche in deutscher Sprache, interdisziplinäre Ausrichtung, komfortabler Einstieg in ein Thema, Orientierung am lokalen Bestand als Kriterien der Literaturerschließung bereits überholt?
Zurückgreifend auf die These, daß es im Online-Katalog einen Kernbestand qualitativer Erschließung mit Indexaten geben soll, der - bei stets möglichem Ausgreifen auf Volltext- und Freitextretrieval - durch Auswahl Klarheit und Überschaubarkeit in der Flut atomisierter Informationen sichert, könnten in dieser mit höherem intellektuellen Aufwand gepflegten Datenschicht dann auch lokale Bestände und Besonderheiten zur Geltung kommen.
Aber auch angesichts zunehmender Komplexität und Differenziertheit des Wissens in der Wissenschaft und der gesamten Informationswelt wären in der Erschließung zwei gute Vorsätze zu empfehlen:
1) Vortrag, gehalten auf dem 86. Dt. Bibliothekartag 1996 in Erlangen (leicht überarbeitet und um bibliographische Anmerkungen ergänzt)
2) Zitat aus dem Referat von Klaus Lepsky "Inhaltserschließung von bibliothekarischen Massendaten" vom Bibliothekartag 1996 in Erlangen
3) Hermann Havekost: Das Problem Sacherschließung durch verbale und systematische Klassifikation. In: Aufbau und Erschließung begrifflicher Datenbanken, Oldenburg 1995, S.91
4) vgl. Gary Marchionini: Information seeking in electronic environments, Cambridge 1995, S.22
5) nach Marchionini, op. cit., S.160
6) Marchionini, op. cit., S.159
7) Havekost, op. cit., S.89
8) vgl. Werner Bies: Pragmatische Inhaltserschließung. In: Konstruktion und Retrieval von Wissen, hrsg. von Norbert Meder u.a., Frankfurt/M. 1995 (Fortschritte in der Wissensorganisation, Bd.3), S.136 f.

{kind=link}