



Virtuelle Fachbibliothek Sozialwissenschaften
Problembereich und Konzeption
Wolfgang Meier, Matthias N.O. Müller, Stefan Winkler
1. Problembereich Hintergrund Die stetig wachsende Vernetzung von Wissenschaft und Forschung auch im sozialwissenschaftlichen Bereich und das rasant steigende Internetangebot der Bibliotheken ermöglichen es schon heute, vom Arbeitsplatz aus in den unterschiedlichsten Bibliotheken (Landes-, Universitäts-, Institutsbibliotheken, Bibliotheken von Forschungseinrichtungen, usw.) und Referenzdatenbanken zu recherchieren. Dabei wird der Benutzer jedoch mit einer Reihe von Problemen konfrontiert: Er muss sich in unterschiedlichen Informationssystemen mit verschiedenen Benutzungsoberflächen und Anfragesprachen zurechtfinden, unterschiedliche Dokumentformate sind zu verarbeiten und nicht zuletzt sollte er die verschiedenen Sacherschließungssysteme beherrschen. Bei der Informationssuche ist es bisher also nötig, dieselbe Anfrage mehrfach unterschiedlich zu formulieren, einzugeben und die verschiedenen Ergebnismengen von Hand nach Duplikaten zu durchsuchen. Diesen Informationsgewinnungsprozess zu vereinfachen und zu beschleunigen ist Ziel der Virtuellen Fachbibliothek Sozialwissenschaften. Für deren Realisierung sind vorrangig drei Problembereiche zu bearbeiten: Aufgabe der Systemarchitektur ist die technische Verbindung der beteiligten Datenbanken, dazu zählen Kommunikationsprotokolle, Datenformate und Dublettenkontrolle. Abschnitt 2 beschäftigt sich näher mit diesem Thema. Die Heterogenitätsproblematik entsteht aus den Unterschieden der beteiligten Sacherschließungssysteme in Art, Struktur, Umfang und Anwendungsgebiet. Abschnitt 3 wird sich näher mit den Problemen und Lösungsstrategien beschäftigen. Da dieser Artikel nur der Übersicht über die Kernproblemstellungen des Projekts dienen soll, werden die Probleme einer Benutzungsoberfläche für verteilte, heterogene Informationssysteme ausgeklammert. Organisation ViBSoz ist ein Gemeinschaftsprojekt des InformationsZentrums Sozialwissenschaften, Bonn (Prof. Dr. J. Krause) und des Instituts für Soziologie der TU Darmstadt (Prof. Dr. R. Schmiede). Weitere Kooperationspartner sind das Sondersammelgebiet Sozialwissenschaften der Universitäts- und Stadtbibliothek Köln, die Bibliothek der Friedrich-Ebert-Stiftung, Bonn, das Zentrum für Interdisziplinäre Technikforschung der TU Darmstadt, sowie der Westdeutsche Verlag, Wiesbaden und der Leske + Budrich Verlag, Leverkusen-Opladen. Im Oktober 1999 hat das Wissenschaftszentrum Berlin (WZB) Interesse geäußert, sich ebenfalls an dem Projekt zu beteiligen und ist mit seinen Datenbeständen einbezogen worden. Die Laufzeit ist zunächst auf zwei Jahre (Mai 1999 bis April 2001) festgelegt, mit einer eventuellen Verlängerung um ein weiteres Jahr. 2. Systemarchitektur Zwei grundlegende Ziele unserer Konzeption sind: Die Projektpartner halten ihre Datenbestände jeweils auf unterschiedlichen Informationssystemen. Vertreten sind relationale Datenbanken, verschiedene Bibliothekssysteme und Volltextdatenbanken. Um erweiterbar zu sein, muss unsere Architektur deshalb von den speziellen Eigenschaften und Möglichkeiten des betreffenden Systems abstrahieren. Damit wir auf diese Systeme über eine einheitliche Schnittstelle zugreifen können, wird das im Bibliotheksbereich verbreitete Z39.50 als Kommunikationsprotokoll verwendet. Dieses Protokoll bietet u.a. eine umfangreiche und wohl-definierte Anfragesyntax und ist zudem gleichermaßen für das Retrieval strukturierter Daten wie für Volltexte geeignet.
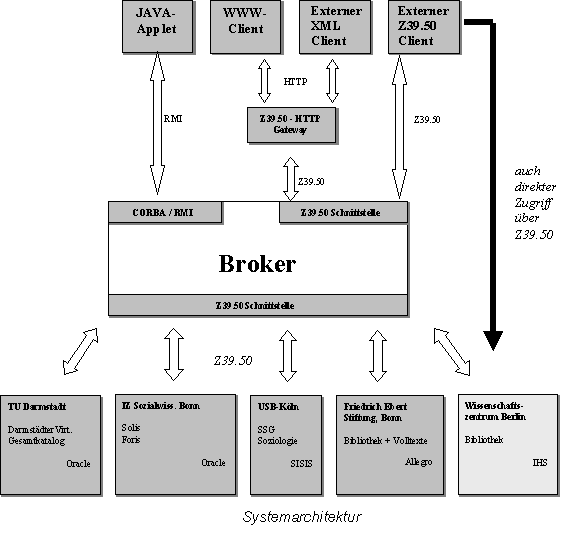
Für verteilte Systeme hat sich eine Broker-Architektur bei vielen Projekten bewährt. Es wird eine oder mehrere zentrale Integrations- und Vermittlungskomponenten (Broker) geben, die von der konkreten Architektur der angesprochenen Informationssysteme unabhängig sind. Der Broker kommuniziert mit den Systemen der Projektpartner ausschließlich über Z39.50. Unterschiede bezüglich Anfragemöglichkeiten, Datenformate etc. werden vom Broker dabei berücksichtigt.
Die Bestände der Projektpartner sollen vor Ort verbleiben, d. h., es ist kein zentraler Datenserver geplant. Zudem werden die lokal bereits existierenden Datenbank- und Bibliothekssysteme nach Möglichkeit genutzt. Da hierbei die Netzlaufzeiten maßgebenden Einfluss auf die Ausführungszeit einer Suche haben, besteht ggf. die Möglichkeit, die Kurztitelsätze einzelner Server auf einem oder mehreren Indexservern zentral zu indizieren, um die wichtigsten Suchvorgänge zu beschleunigen.
Angeschlossen sind derzeit die USB Köln, die einen Z39.50-Zugang zu ihrem SISIS-OPAC bereitgestellt hat, das IZ Bonn mit den Datenbanken SOLIS/ FORIS und die TU Darmstadt mit den Beständen des Darmstädter Virtuellen Gesamtkatalogs. Hinzukommen werden die Friedrich-Ebert-Stiftung, die ihre Daten über die Z39.50-Schnittstelle des Allegro-Servers anbieten wird, sowie das Wissenschaftszentrum Berlin, an dem BRS/Search der Firma IHS im Einsatz ist.
IZ Bonn und TU Darmstadt halten ihre Daten auf Oracle-Datenbanken. Um auf diese Daten über Z39.50 zugreifen zu können, wurde von uns ein eigener Z39.50-Server implementiert. Der Server dient zunächst dazu, ankommende Z39.50-Anfragen auf die entsprechenden SQL-Anfragen umzusetzen, bzw. Datensätze in verschiedenen Formaten (UNIMarc, MAB, XML) aus der Datenbank auszugeben. Der Z39.50-Server wurde so implementiert, dass er auch außerhalb des Projekts von Nutzen sein kann, sowohl, um andere Datenbanksysteme mit einer Z39.50-Schnittstelle auszustatten, als auch, um eine Übersetzung zwischen Z39.50 und anderen Protokollen zu gewährleisten.
An der TU Darmstadt wurde ein erster Prototyp der Broker-Komponente fertiggestellt. Sie befindet sich derzeit noch in einem frühen Entwicklungsstadium, die grundlegende Funktionalität ist jedoch bereits implementiert. Der Broker führt eine parallele Abfrage der angeschlossenen Server durch und führt die Ergebnisse zusammen. Dabei werden die Treffermengen sortiert und Dubletten ausgefiltert.
Da die teilnehmenden Server unterschiedliche Datenformate (Marc, MAB, XML) unterstützen, werden alle Titelsätze zunächst in ein internes Format transformiert. Dieses interne Format basiert auf XML: Die Verwendung von XML erlaubt uns, möglichst viele unterschiedliche Datensatzstrukturen verarbeiten zu können. Der Broker muss lediglich wissen, wie er die für Sortierung und Dublettenkontrolle notwendigen Informationen (Titel, Autor, ISBN etc.) aus dem jeweiligen Datensatz gewinnen kann. Die Konvertierung von XML nach Marc, MAB etc. und umgekehrt wird durch edierbare Stylesheets erledigt, wodurch Anpassungen ohne Änderungen am Programmcode möglich sind.
Der Broker benötigt detaillierte Informationen über die angeschlossenen bzw. ansprechbaren Server und ihre jeweiligen Eigenschaften und Fähigkeiten. Derzeit werden solche Daten über eine Konfigurationsdatei eingelesen. Zukünftig soll es jedoch einen zentralen Manager für die Server-Profile geben, der die Server-Beschreibungen dynamisch verwalten kann, so dass Änderungen im laufenden Betrieb durchzuführen sind.
Aus Sicht eines Clients ist der Broker selbst wieder ein "normaler" Z39.50-Server und kann von jeder Z39.50-fähigen Software angesprochen werden. Durch die offene Architektur können die Benutzer zwischen diversen Möglichkeiten des Zugriffs wählen, z. B. über eine komfortable Java-Oberfläche, eine Web-Schnittstelle, Programme zur Literaturverwaltung (z. B. EndNote) oder über Bibliothekssoftware mit entsprechender Schnittstelle (z. B. Allegro/Alcarta).
3. Heterogenitätsbehandlung
Neben dem im Kapitel 2 besprochenen Problem der Integration verschiedener Datenbanken und Datenformate im Rahmen einer Z39.50-fähigen Systemarchitektur ist die Integration der verschiedenen Sacherschließungssysteme durch Transferkomponenten der zweite Schwerpunkt des Projekts.
3.1 Sacherschließungssysteme
Im Projekt Virtuelle Fachbibliothek Sozialwissenschaften ist eine Vielzahl von Sacherschließungssystemen vertreten. Das Spektrum reicht von allgemeinen Regelwerken, wie der Schlagwortnormdatei (SWD), über fachspezifische, wie den Thesaurus Sozialwissenschaften (IZ-Thesaurus), bis zu freien Schlagwörtern. Gleiches gilt für die Klassifikationen, die mit verschiedenen Ausprägungen der Basisklassifikation (BK) als Allgemeinklassifikation, der Klassifikation Sozialwissenschaften (IZ-Klassifikation) als Fachklassifikation und den weniger spezifischen Aufstellsystematiken im Projekt vertreten sind.
Um einen Querschnitt der in der Bibliothekslandschaft vorkommenden Sacherschließungssysteme abzudecken, werden zunächst die Schlagwortnormdatei, der Thesaurus Sozialwissenschaften und das Regelwerk der FES im Bereich der Verbalerschließung, die Basisklassifikation sowie die Klassifikation Sozialwissenschaften im Bereich der Klassifikation für die Heterogenitätsbehandlung bearbeitet.
3.2 Transfermodule
Die Vielfalt der verwendeten Systeme für die inhaltliche Beschreibung von Dokumenten erzeugt für den Benutzer Probleme bei der Suche nach Information. Möchte er in allen beteiligten Beständen eine tiefergehende Suche durchführen, so war er bisher gezwungen, alle verwendeten Sacherschließungssysteme zu erlernen. Er kann nicht einfach das ihm vertraute System auf die anderen Bestände übertragen.
Neben dem Problem der Synonymie (auch und besonders im Bereich der Namen und Bezeichnungen) sind auch die strukturellen Probleme der unterschiedlichen Einbettung der Begriffe in Thesauri und Klassifikation sowie das Problem der Verbindung von pre- und postkoordinierten Systemen zu lösen.
Aufgabe des zu entwickelnden Systems ist die Unterstützung des Benutzers bei der "Übersetzung" von einem Sacherschließungssystem zum anderen. Idealtypischerweise geschieht diese Übersetzung innerhalb des Systems, so dass der Benutzer zwar auf Wunsch darüber informiert wird, nicht aber selbst eingreifen muss. Er kann seine Anfragen an das Gesamtsystem in seiner gewohnten Weise formulieren. Die Umsetzung bzw. Anpassung an die verschiedenen beteiligten Systeme erfolgt dann automatisch. Der Benutzer muss also nicht mehr alle Sacherschließungssysteme kennen.
Transfermodule ermöglichen somit den konsistenten Übergang zwischen den verschiedenen Ebenen des Schalenmodells (Krause 1999).
Cross-Konkordanzen
Eine Möglichkeit, eine solche Umsetzung zu realisieren, ist die Verwendung von Cross-Konkordanzen. Die intellektuelle Verbindung zweier Sacherschließungssysteme ermöglicht neben der Erfassung von Synonymierelationen auch Oberbegriffs-/ Unterbegriffs- und Ähnlichkeitsrelationen. Der Aufwand und die Kosten einer solchen intellektuellen Bearbeitung sind jedoch recht hoch. Zudem müssen die Ergebnisse, bedingt durch den ständigen Wandel der Systeme, periodisch überprüft und angepasst werden.
Im Projekt ist zunächst eine (partielle) intellektuelle Cross-Konkordanz zwischen der SWD und dem Thesaurus Sozialwissenschaften sowie der Basisklassifikation und der Klassifikation Sozialwissenschaften vorgesehen. Die Arbeiten daran haben bereits begonnen, und erste Beispiele liegen vor.
Quantitativ-statistische Verfahren
Eine andere Möglichkeit einer solchen Umsetzung ist der Einsatz automatischer, quantitativ-statistischer Verfahren, die den Transfer zwischen dem Sacherschließungssystem der Benutzereingabe und den Sacherschließungssystemen der anderen Datenquellen berechnen. Dabei werden die jeweiligen Begriffspaare nicht nach qualitativen Maßstäben erzeugt, wie bei der intellektuellen Erstellung, sondern nach ihrer Quantität bezogen auf ein Korpus, also nach der Häufigkeit ihres Vorkommens. Vereinfacht ausgedrückt: Je häufiger ein Begriffspaar in einem Korpus vorkommt, desto wahrscheinlicher ist es, dass es sich um eine sinnvolle Verbindung handelt. Hinzu kommen Parameter wie die Größe des Korpus oder die Verteilung der Begriffe innerhalb desselben.
Voraussetzung für dieses Verfahren ist ein Korpus, in dem die Dokumente nach beiden Sacherschließungssystemen indexiert sind (Parallelkorpus). Er entsteht durch den Abgleich zweier Korpora und die Extraktion von Paaren gleicher Dokumente. Jedes Dokument (-paar) ist dann nach zwei Erschließungssystemen indexiert.
Aus einem solchen Korpus werden dann Relationen zwischen einzelnen oder Gruppen von Schlagwörtern / Klassifikationen abgeleitet. Als Verfahren hierfür werden in ViBSoz vorwiegend statistische Verfahren eingesetzt, experimentell aber auch Neuronale Netze.
Statistische Verfahren analysieren im Prinzip die Häufigkeit des gemeinsamen Auftretens zweier Schlagwörter1 innerhalb des Parallelkorpus und übertragen die gewonnenen Relationen später auf neue Dokumente. Vergleicht man dabei zwei Schlagwörter aus unterschiedlichen Sacherschließungssystemen, so lassen sich statistische Abhängigkeiten zwischen den einzelnen Begriffen und somit zwischen den Sacherschließungssystemen ermitteln.
Für das Dokument "Gysi, Jutta: Familienleben in der DDR, zum Alltag von Familien mit Kindern, Akademie Verlag Berlin, 1989, ISBN 3-05-000771-0 ." zum Beispiel, wurden an der USB Köln die Schlagwörter 'Deutschland <DDR>' und 'Familie' vergeben. Im IZ-Sozialwissenschaften erhielt das gleiche Dokument die Schlagwörter 'Arbeitsteilung', 'Ehe', 'Familie', 'DDR' und 'Partnerschaft'. Bei diesem Dokument treten also unter anderem das SWD-Schlagwort 'Deutschland <DDR>' und das IZ-Schlagwort 'DDR' gemeinsam auf. Ist dieses gemeinsame Auftreten auch bei anderen Dokumenten zu beobachten, so handelt es bei diesem Begriffspaar höchstwahrscheinlich um eine sinnvolle Transferbeziehung. Tatsächlich tritt dieses Paar im derzeitigen Parallelkorpus von USB Köln und IZ Sozialwissenschaften noch bei 272 weiteren Dokumenten auf.
Wie aus der Statistik bekannt, reicht diese absolute Häufigkeit jedoch nicht aus, um die Güte einer solchen Transferbeziehung zu bestimmen. Sie muss z. B. mit der Häufigkeit der Vorkommen der Terme oder der Gesamtzahl der Relationen in Bezug gesetzt werden. Dazu werden in ViBSoz bedingte Wahrscheinlichkeit und Äquivalenzindex getestet.
Die bedingte Wahrscheinlichkeit ist die Wahrscheinlichkeit, mit der ein Begriff B aus dem Sacherschließungssystem X auftaucht, wenn auch der Begriff A aus dem Sacherschließungssystem Y aufgetaucht ist. Bezogen auf unser Beispiel ist es dann die Frage: Wie wahrscheinlich ist es, dass der IZ-Term 'DDR' vergeben wurde, wenn die USB Köln den Term 'Deutschland <DDR>' vergeben hat. Verwendung findet dieses Vorgehen z. B. im System AIR/PHYS (Biebricher et al. 1988), das sich mit automatischer Indexierung befasst.
Der Äquivalenzindex hat seinen Ursprung in der Kookkurrenzanalyse und findet heute vielfältige Verwendung.2 Er bezieht, im Gegensatz zur bedingten Wahrscheinlichkeit, auch die Vorkommenshäufigkeit des zweiten Terms in die Berechnung mit ein.
Zur Zeit werden die beiden Verfahren exemplarisch anhand des Parallelkorpus USB Köln IZ Sozialwissenschaften geprüft und es werden Vorgehen entwickelt, die entsprechenden Schwellenwerte, ab wann eine Transferbeziehung als sinnvoll zu betrachten ist, zu bestimmen. Erste Ergebnisse sind sehr vielversprechend.
4. Ausblick
Mit dem fertigen System soll dem Benutzer die Möglichkeit gegeben werden, in nur einem Suchvorgang in unterschiedlichen, heterogenen und verteilten Datenbeständen zu recherchieren. Er wird die ihm vertraute Sacherschließung nutzen können, d. h., das System wird in der Lage sein, die vom Benutzer gestellte Anfrage adäquat in andere Sacherschließungen umzusetzen. Das Ergebnis wird konsistent und dublettenfrei präsentiert, wobei jeder Datensatz aus der Information der einzelnen Systeme zusammengesetzt ist. Es ist also eine große Arbeitserleichterung und ein echter informationeller Mehrwert zu erwarten.
Nächster Schritt bei der Umsetzung der Projektziele ist die rasche Integration und Ergänzung der vorliegenden Teile zu einem weitgehend funktionsfähigen Prototyp. Auf seiner Basis können die erarbeiteten Verfahren getestet, verbessert und generalisiert werden.
Im Bereich des Brokers liegen die Schwerpunkte zum einen bei der Integration der noch fehlenden Datenbestände der Friedrich-Ebert-Stiftung und des Wissenschaftszentrums Berlin. Zum anderen werden die Verfahren zur Ergebniszusammenführung verbessert.
Im Bereich der Transferkomponenten stehen die Implementierung und Einbettung der erarbeiteten Cross- und statistischen Konkordanzen in das Gesamtsystem an nächster Stelle. Die Verfeinerung der statistischen Verfahren zur Erstellung der statistischen Konkordanzen und ihre Anwendung auf die noch verbleibenden Sacherschließungssysteme zählen zu den nächsten Schritten.
Somit ist in den kommenden Monaten mit der Fertigstellung eines funktionsfähigen Prototyps zu rechnen, der dann zur Evaluation zur Verfügung steht.
Weitere Information zum Projekt findet sich im WWW unter: http://vibsoz.bonn.iz-soz.de
Literatur
Biebricher P., Fuhr, N., Lustig, G., et al. (1988). The Automatic Indexing System AIR/PHYS - From Research to Application. In: 11th International Conference on Research & Development in Information Retrieval. Grenoble 1988.
Grievel, L., Mutschke, P. und Polanco, X. (1995). Thematic Mapping on Bibliographic Databases by Cluster Analysis: A Description of the SDOC Environment with SOLIS. Knowledge Organisation 22: 8.
Krause, J. (1999). Sacherschließung in virtuellen Bibliotheken. Standardisierung versus Heterogenität. In: Grenzenlos in die Zukunft. 89. Deutscher Bi-
bliothekartag in Freiburg im Breisgau 1999. Frankfurt am Main, 2000. (ZfBB-Sonderheft 77).
1 Im Weiteren wird das Vorgehen bei der Analyse von Paaren einzelner Schlagwörter betrachtet. Gleiches gilt aber für Klassifikationen und Gruppen von Schlagwörtern / Klassifikationen.
2 Siehe zum Beispiel (Grievel/Mutschke/Polanco 1995).
