




Wilfried Enderle, Frank Schulenburg, Gaby Weigang
1. Einleitung
Wissenschaftliche Bibliotheken haben bislang in Deutschland für ihre Nutzer in erster Linie ihre monographischen Bestände in (Online-) Katalogen erschlossen. Die Erschließung der eigenen Zeitschriften war bislang hingegen ausschließlich eine Domäne von Spezialbibliotheken und Dokumentationseinrichtungen oder auch von Sondersammelgebietsbibliotheken, die dies dann für ihren Sammelschwerpunkt taten. Der Tübinger Zeitschrifteninhaltsdienst Theologie ist nur ein Beispiel hierfür. Zunehmend werden jetzt aber auch - was im angloamerikanischen Raum bereits seit einiger Zeit verbreitet ist - Datenbanken mit Zeitschriftenaufsatzdaten, die zumeist von größeren, kommerziellen Lieferanten erworben werden, aufgelegt. Die vom Bibliotheksrechenzentrum Niedersachsen für den GBV aufgelegte Online-Contents-Datenbank oder JADE in Nordrhein-Westfalen sind Beispiele hierfür.
Sowohl bei diesen Zeitschrifteninhaltsdatenbanken wie auch bei den verschiedenen Erschließungsdiensten muß freilich zwischen unterschiedlichen Formen und Qualitätsstandards differenziert werden. So können Zeitschrifteninhaltsdienste eine reine Current-Contents-Funktionalität bieten; in diesem Fall müssen sie den gesamten Inhalt eines Zeitschrifteninhaltsverzeichnisses, einschließlich dort aufgeführter Rezensionen, wiedergeben. Die kopierte Reproduktion des Originalinhaltsverzeichnisses war - und ist zum Teil immer noch - eine der gebräuchlichsten Formen eines solchen Dienstes. Ein Zeitschrifteninhaltsdienst kann aber auch fachbibliographischen Zwecken dienen. In diesem Fall ist eine entsprechende Sacherschließung Voraussetzung, die sich dann - naturgemäß - nur auf die reinen Aufsatzdaten beziehen kann. Werden diese Daten von Bibliotheken über Online-Kataloge angeboten, ist für deren Qualität von Bedeutung, inwieweit mit den Daten Besitz- und Standortnachweise verbunden sind, der Benutzer also mit der Recherche bereits auch über die Information, wie er an diesen Aufsatz gelangen kann, verfügt.
Sowohl Current-Contents-Dienste als auch eine fachbibliographisch orientierte Zeitschrifteninhaltserschließung sind zumeist in organisatorischer wie technischer Hinsicht eigenständige, isolierte Unternehmungen einzelner Bibliotheken oder Fachinformationszentren, die zum Teil für einen hochspezialisierten Benutzerkreis durchgeführt werden. Der derzeitige technische Stand der Datenverarbeitung wie auch der bibliothekarischen Verbundsysteme erlauben es indes, diese Begrenzungen zu überwinden. So liegt es nahe, daß Bibliotheken bei der Erstellung solcher Dienste miteinander kooperieren, zumal mit der Verbundkatalogisierung eingeführte und erfolgreiche Modelle hierfür vorliegen.
Das derzeit an der Niedersächsischen Staats- und Universitätsbibliothek Göttingen durchgeführte und von der Deutschen Forschungsgemeinschaft geförderte Projekt "SSG-S-Current-Contents Nordamerika" stellt einen Versuch dar, einen zeitgemäßen Current-Contents-Dienst am Beispiel eines Sondersammelgebietes im Rahmen eines bibliothekarischen Verbundsystemes aufzubauen. Die Daten werden dafür mittels eines Scanners erfaßt, mit Hilfe von OCR-Software automatisch in ASCII-Zeichen konvertiert und dann halbautomatisch in ein bibliothekarisches Datenformat umgewandelt. Diese Daten werden dann in die Online-Contents-Datenbank des GBV importiert und können über das lokale Bibliothekssystem der SUB Göttingen von den Benutzern recherchiert und - unter anderem - für Aufsatzbestellungen genutzt werden.
Das SSG-S-Current-Contents-Projekt ist dabei, wie der Name schon zeigt, als komplementäres Unternehmen zu dem "Sondersammelgebiets-Schnelldienst-Projekt" (SSG-S-Projekt) zu sehen, das derzeit von vier Bibliotheken, den Universitätsbibliotheken Tübingen und Saarbrücken sowie der Senckenbergischen Bibliothek in Frankfurt und der SUB Göttingen jeweils für ausgewählte Sondersammelgebiete durchgeführt wird. Im Rahmen dieser Projekte wird beispielhaft ein Dokumentlieferdienst von SSG-Bibliotheken direkt für den Endnutzer aufgebaut. Der Current-Contents-Dienst, der parallel hierzu am Beispiel des SSG-S Nordamerika realisiert wird, hat dabei - neben dem eigentlichen Current-Contents-Dienst - auch die Funktion einer Bestellgrundlage für Online-Bestellungen.
Vor diesem Hintergrund ist auch die spezifische Konzeption und Zielsetzung des Current-Contents-Projektes zu sehen: Da das Projekt komplementär zum Dokumentlieferprojekt (SSG-Schnelldienst) durchgeführt wird und hierfür auch bereits Daten als Bestellgrundlage benötigt werden, war eine rasche technische Umsetzung notwendig. Es mußte damit eine einfache technische Lösung gefunden werden, die auf vorhandener Standardsoftware basiert, und die damit zugleich den Vorteil hat, von anderen Bibliotheken - unabhängig von deren konkreter technischer Ausstattung - leicht nachnutzbar zu sein. Zugleich sollte der Vorgang der Erfassung der Zeitschrifteninhaltsverzeichnisse soweit wie möglich mittels des Einsatzes eines Scanners und einer OCR-Komponente automatisiert werden. Es werden dabei nur solche Zeitschriften erfaßt, die so speziell sind, daß sie nicht über kommerzielle Lieferanten zu beziehen sind.
Neben der raschen Produktion von Current-Contents-Daten ist ein weiteres Ziel die Analyse und Auswertung des Projektes unter betriebswirtschaftlichen Gesichtspunkten. So stellt sich natürlich die Frage, wie aufwendig ein solcher Dienst ist, welche konkreten Kosten entstehen und ob das Ergebnis für den Nutzer den personellen und technischen Einsatz lohnt. Damit wird auch ein konkreter Vergleich mit den kommerziellen Anbietern möglich.
Die Konzeption des Projektes ist auch vor dem Hintergrund der Möglichkeiten des lokalen PICA-Systems der SUB Göttingen sowie dem PICA-Zentralsystem des GBV zu sehen. Im zentralen Verbundsystem ist neben der Katalogisierungsdatenbank der Monographien eine sogenannte "Online-Contents-Datenbank" aufgebaut worden, welche die laufend aktualisierten Inhaltsdaten von zur Zeit ca. 12.000 Zeitschriften enthält. Diese zentrale Datenbank bietet auf Verbundebene eine Current-Contents-Funktionalität und ist zugleich in das elektronische Fernleih- und Dokumentliefersystem des Verbundes integriert. Von dieser zentralen Datenbank werden in das lokale Datenbanksystem der SUB Göttingen diejenigen Daten übertragen, für die Göttinger Besitz nachgewiesen ist. Im Rahmen des Current-Contents-Projektes Nordamerika werden nun zusätzlich Datensätze für die zentrale Online-Contents-Datenbank erstellt, die von dort in den lokalen OPAC übertragen werden, wo sie dann mit den üblichen Zugriffsmöglichkeiten für die Benutzer zur Verfügung stehen - sowohl für die lokalen Göttinger Benutzer als auch via Internet (WWW oder Telnet), WIN oder Modem-Anschluß.
2. Die technische Konzeption des Projektes
Wie werden nun diese Inhaltsdaten konkret erstellt? Technischer Ausgangspunkt ist ein Fuijutsu-Flachbettscanner, mit dem die Inhaltsverzeichnisse - also Aufsatz- sowie Reviewdaten - gescannt werden. Anschließend werden die so erzeugten Bilddateien mittels eines OCR-Programmes in ASCII-Zeichen konvertiert und als Datei abgelegt. Als OCR-Programm wird dabei Omnipage Pro 6.0 eingesetzt, das unter MS-Windows 3.1 läuft. Die in einer Datei abgelegten, unstrukturierten Textdaten werden anschließend in ein eigens entwickeltes, ebenfalls unter Windows lauffähiges Current-Contents-Tool geladen, wo in einem manuellen Durchgang alle Autoren- und Titeldaten mit einem definierten Zeichen markiert und anschließend automatisiert in das Format der Online-Contents-Datenbank - unter automatischer Hinzufügung der notwendigen Identnummern und Erscheinungsdaten (Band, Heft, Jahr) - konvertiert und wiederum in eine Exportdatei abgelegt werden.
Nach dem Scannen der Zeitschrifteninhaltsverzeichnisse und der anschließenden Texterkennung durch ein OCR-Programm liegen die aus dem Inhaltsverzeichnis gewonnenen Daten mithin ungeordnet in einer Textdatei vor. Ein wichtiger Arbeitsgang ist daher die nachfolgende Erzeugung von Datensätzen im PICA-Format, d.h. das Ordnen von Titel-, Autor- und Seitenangaben sowie die nötige Ergänzung von Kategorienbezeichnungen und zeitschriftenabhängigen Daten wie ZDB-ID, Band- und Heftnummer, welche durch das Current-Contents-Tool bewerkstelligt wird. Eine vollautomatische Umwandlung von Inhaltsverzeichnisdaten zu PICA-Datensätzen ist dabei aufgrund der praxisorientierten Zielsetzung des Projektes nicht in Betracht gezogen worden, da dies programmtechnisch aufwendige Lösungen erforderte. Deshalb stand bei der Entwicklung des Programmes für den Bereich der Bearbeitung von Inhaltsverzeichnissen der bedienerunterstützende Aspekt an erster Stelle. Wichtigster Schritt bei der Arbeit mit dem Current-Contents-Tool ist das Markieren von Titel- und Autorenbezeichnungen. Hierzu stellt das Programm einen eigenen Texteditor zur Verfügung (vgl. Abb. 1).
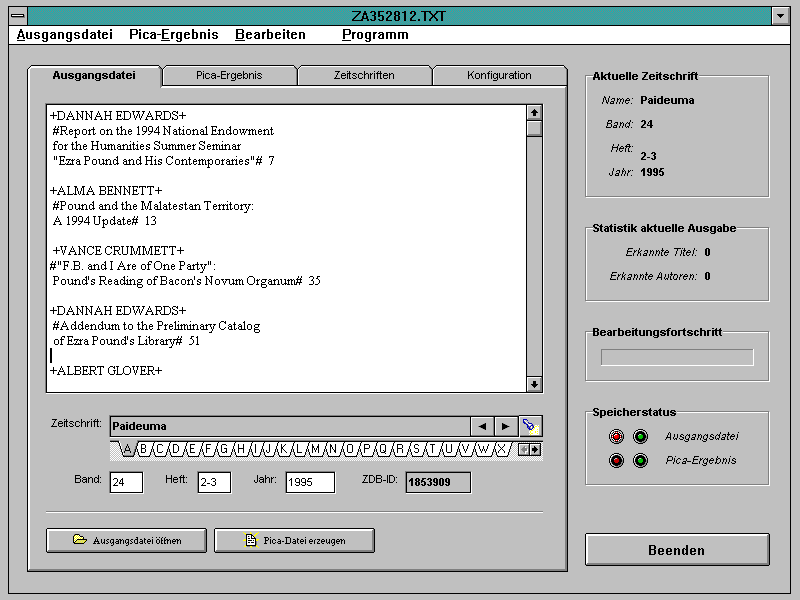
Abb.1 : Das Markieren von Titeln und Autoren im Texteditor
Nachdem das Markieren von Titeln und Autoren im Texteditor abgeschlossen ist, gibt der Benutzer Band- und Heftnummer sowie das Erscheinungsjahr der Zeitschrift in die dafür vorgesehenen Felder ein. Anschließend wird durch einen einfachen Mausklick die halbautomatische Erkennung ausgelöst. Nach einer Überprüfung des Textes auf Markierungsfehler (zu wenige bzw. zu viele Markierungszeichen, keine Übereinstimmung in der Anzahl der Titel und Autoren) ergänzt das Programm die Kategorien nach dem festgelegten Schema und erzeugt so die Datensätze im PICA-Format. Nichtvariable Zeitschriftendaten wie die ZDB-ID entnimmt das Programm dabei einer implementierten kleinen Datenbank der Current-Contents-Zeitschriften. Die im Text enthaltenen Seitenangaben werden durch das Tool automatisch erkannt und den Datensätzen hinzugefügt. Nachdem die halbautomatische Erkennung durchlaufen wurde, können die Datensätze in einem zweiten Editorfenster - sofern notwendig - nachbearbeitet werden. Die Speicherung erfolgt als Textdatei im ASCII-Format; durch eine Modifikation des Programmes ist jedoch auch die Speicherung in jedem anderen Dateiformat denkbar.
Das Tool belegt zusammen mit einer Zeitschriftendatenbank, in der etwa 500 Zeitschriften gespeichert sind, weniger als 1 Megabyte auf der Festplatte. Da die Verwendung eines unter Microsoft Windows 3.x laufenden Texterkennungsprogrammes vorausgesetzt wurde, ist das Current-Contents-Tool ebenfalls für die Windows-Plattform konzipiert. Dabei macht es keinen Unterschied, ob Windows 3.x oder Windows 95 eingesetzt wird. Da OS/2 ab Version 3.0 ebenfalls Windows-Programme unterstützt, ist das Tool auch unter diesem Betriebssystem einsatzfähig. Die Geschwindigkeit des Programms ist vor allem von der Prozessorleistung abhängig. Sinnvoll wird der Einsatz ab einem 80386-Prozessor, empfehlenswert ist jedoch eher eine höhere Prozessorklasse.
Das Current-Contents-Tool ist vollständig in Pascal geschrieben. Entwickelt wurde das Programm unter Delphi 1.0 von Borland. Die Programmierung in Pascal bietet den Vorteil, daß das Programm leicht an spezielle Bedürfnisse angepaßt werden kann.
3. Geschäftsgang und Katalogisierungsaspekte
Zur Zeit werden im Rahmen des Projektes ca. 500 Zeitschriften bearbeitet, wobei sowohl die laufend eintreffenden neuen Hefte als auch retrospektiv der Jahrgang 1995 erfaßt wird. Das eigentliche Bearbeiten der Zeitschriften: Scannen der Inhaltsverzeichnisse, automatische Texterkennung und anschließende Erzeugung von PICA-Daten mit Hilfe des Current-Contents-Tools wird von studentischen Hilfskräften durchgeführt. Dabei werden alle Daten des Inhaltsverzeichnisses erfaßt. Nicht aufgenommen werden nur folgende Rubriken: Stellenanzeigen, Indices, Überschriften mehrerer Aufsätze, Preisvergaben, Buchbesprechungen, wenn weder Titel noch Autor des Buches genannt sind. Ganz allgemein werden Zeitschriften, die reine Primärliteratur enthalten, nicht ausgewertet.
Die so entstandenen Dateien werden von einer bibliothekarischen Fachkraft auf ihre Korrektheit überprüft. Gleichzeitig erfolgt das Führen von Statistikangaben über Zeitschriftenhefte und Zahl und Dauer der Arbeitsschritte mit Hilfe eines Statistikprogrammes. Die Produktion einer Woche wird jeweils als Textdatei an das Bibliotheksrechenzentrum Niedersachsen (BRZN) geliefert.
Zeitschriftenaufsätze stellen aus der Perspektive der Katalogisierung eine einfache Aufgabe dar, wie bereits das Datenformat zeigt, das sich auf wenige, notwendige Kategorien, wie Name, Titel, Erscheinungsjahr usw. beschränkt.
In der Praxis stellen sich natürlich immer wieder weitere Detailfragen, wie z. B. die Bearbeitung von Inhaltsverzeichnissen, bei denen die Autoren nicht eigens aufgeführt, sondern erst bei den jeweiligen Beiträgen genannt werden. Hierbei handelt es sich indes zumeist um Probleme, die sich nur schwer typisieren lassen. Deren Bearbeitung muß daher im jeweiligen Einzelfall geprüft und entschieden werden.
4. Ausblick: Kooperative Zeitschrifteninhaltserschließung im Verbund?
Auch wenn zur Zeit noch keine endgültigen Aussagen über die Bearbeitungseffizienz getroffen werden können, so steht doch fest, daß bei einem Volumen von ca. 3.500 Datensätzen pro Monat die Erfassung mittels eines Scanners und die halbautomatisierte Datensatzerstellung die Möglichkeiten manueller Eingaben übertreffen. Genauer untersucht werden muß natürlich noch die Frage, inwieweit kommerzielle Lieferanten noch günstiger arbeiten. Unabhängig vom Ausgang dieses Vergleiches ist es aber klar, daß spezielle Zeitschriften, die nur von Sondersammelgebiets- und Fachbibliotheken erworben werden, auf alle Fälle von diesen Einrichtungen selbst erfaßt werden müssen, da es hierfür kaum kostengünstige kommerzielle Angebote in ausreichendem Umfang geben wird.
Neben der durch den Einsatz technischer Hilfsmittel verbesserten Erfassung ist dabei entscheidend, daß die Daten im Verbund zur Verfügung stehen. Damit stellt sich natürlich die Frage, ob nicht generell die Zeit dafür reif wäre, daß die Bibliotheken kooperativ im Verbund auch ihre Zeitschriften für den Nutzer erschließen. Dabei kann es sich natürlich zunächst nicht um eine fachbibliographische Erschließung handeln, sondern nur um die elektronische Aufbereitung der eigentlichen Inhaltsdaten, also um eine echte Current-Contents-Funktionalität. Zehn Bibliotheken, die jeweils 500 unterschiedliche Zeitschriften erfassen, könnten bereits ein beachtliches Potential erschließen, das zusätzlich - oder in Konkurrenz? - zu kommerziell erwerbbaren Daten aufgelegt werden könnte. Neben der Current-Contents-Funktionalität könnten solche Daten zum Beispiel auch Basis für eine fachliche Erschließung durch personell entsprechend ausgestattete Bibliotheken oder Fachinformationszentren und vergleichbare Einrichtungen sein. Dort könnte man sich das eigentliche Erfassen der Daten sparen und sich dafür auf die inhaltliche Erschließung konzentrieren. Bibliotheken und Fachinformationseinrichtungen könnten so - endlich einmal - im Rahmen eines arbeitsteiligen Konzeptes Hand in Hand arbeiten.
Perspektiven für Nutzungsmöglichkeiten des SSG-S-Current-Contents-Projektes gibt es sicherlich viele. Es bleibt zu hoffen, daß die Bibliotheken sich auch zu einem gemeinsamen und kooperativen Vorgehen verständigen können. Welche technischen Konzeptionen letztlich eingesetzt werden, ist dabei zweitrangig. Entscheidend dürfte sein, daß das Ergebnis, die elektronischen Zeitschrifteninhaltsdaten, ohne Doppelerfassung in gemeinsame Datenpools eingespielt und den Nutzern zur Verfügung gestellt werden.
